




به گزارش کارگروه حملات سایبری سایبربان؛ کارشناسان اعلام کردند که در 6 فوریه امسال، چندین سرویس شرکت مدیریت سرویس فناوری اطلاعات «Cloudflare»، از جمله «R2»، به مدت 59 دقیقه از دسترس خارج شدند. این امر باعث شد تا تمام عملیاتها در طول مدت حادثه با شکست مواجه شوند و برخی سرویسهای دیگر Cloudflare، وابسته به R2، از جمله «Stream»، «Images»، «Cache Reserve»، «Vectorivery» و «Log»، دچار قطعی گسترده شوند.
محققان معتقدند که این حادثه به دلیل خطای انسانی و آموزشهای اعتبارسنجی ناکافی در طول گزارشی درباره یک سایت فیشینگ میزبانی شده در R2 رخ داد. اقدام انجام شده در مورد شکایت منجر به غیرفعال کردن محصول پیشرفته در سایت و سرویس تولید «R2 Gateway» مسئول «API R2» شد.
به گفته کارشناسان، این حادثه منجر به از بین رفتن یا خراب شدن هیچ یک از دادههای ذخیره شده در R2 نشد.
Cloudflare در این خصوص مقالهای منتشر کرد که به شرح زیر است:
«ما عمیقاً برای این حادثه متأسف هستیم: این شکست برخی کنترلها بود و ما در حال اولویتبندی کار برای اجرای کنترلهای اضافی در سطح سیستم، مرتبط با سیستمهای پردازش سوءاستفاده و روند کاهش شعاع تأثیر بر هر سیستم یا عمل انسانی هستیم که میتواند منجر به غیرفعال کردن هر سرویس تولیدی در Cloudflare شود.
چه چیزی تحت تأثیر قرار گرفت؟
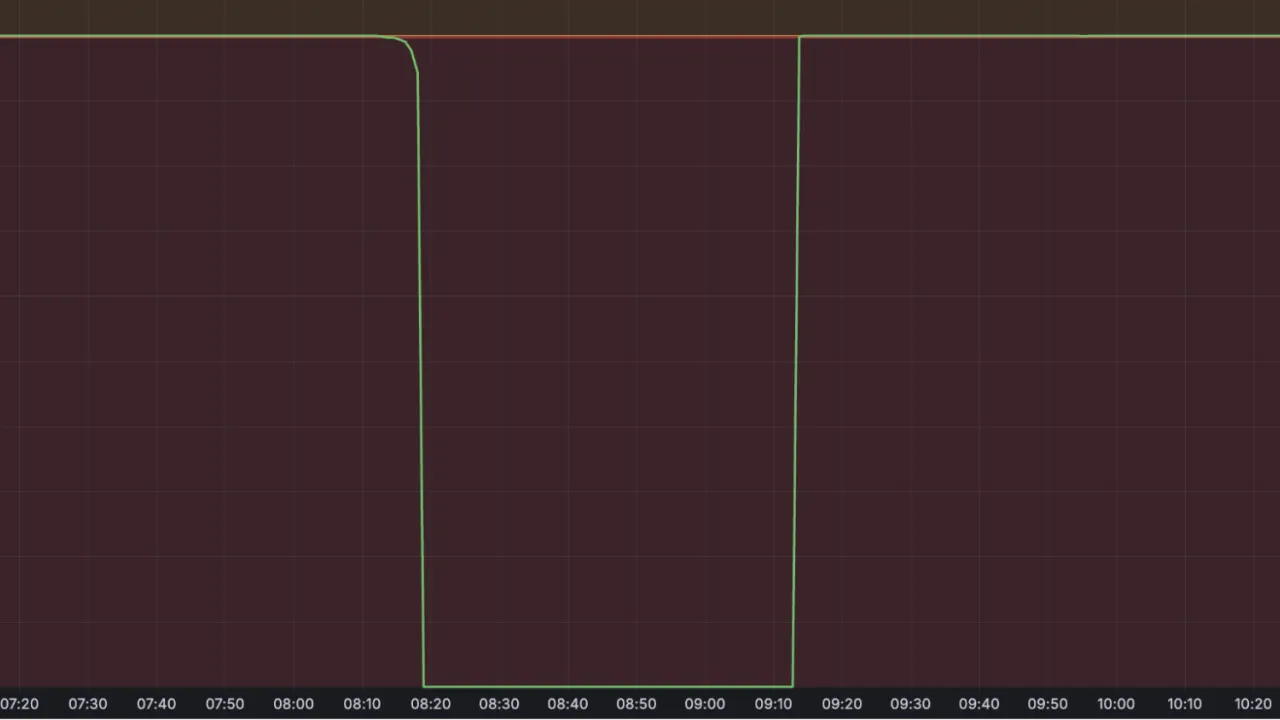
همه مشتریانی که از Cloudflare R2 استفاده میکنند، در حادثه اولیه، نرخ خرابی 100 درصد را برای R2 مشاهده میکنند. سرویسهای وابسته به R2، بسته به نوع استفاده از این سیستم، نرخ خطا و حالتهای خرابی افزایش یافته را مشاهده کردند.
پنجره حادثه اولیه زمانی رخ داد که عملیات علیه R2 دارای ضریب خطای 100 درصد بود. سرویسهای وابسته، افزایش نرخ شکست را برای عملیاتهای متکی به R2 مشاهده کردند.
با بهبود R2 و اتصال مجدد کلاینتها، سرعت عملیاتهای مشتری باعث مشکلات بارگذاری در لایه ابرداده R2 (ساخته شده روی اشیاء پایا) شد. شرکت در طول این پنجره شاهد افزایش 0.09 درصدی نرخ خطا در تماسها با اشیاء پایا در آمریکای شمالی بود.
جدول زمانی حادثه و تأثیر آن
جدول زمانی حادثه، از جمله تأثیر اولیه، بررسی علت اصلی و اصلاح، در زیر به تفصیل آمده است:
تمام زمانهای اشاره شده مطابق با ساعت هماهنگ جهانی (UTC) هستند.
در سطح خدمات R2، معیارهای داخلی «Prometheus» ما نشان داد که «SLO R2» تقریباً بلافاصله به صفر درصد کاهش یافت، زیرا سرویس Gatewayخدمترسانی را متوقف کرد و درخواستهای حین پرواز را خاتمه داد.
تأخیر جزئی در شکست به دلیل عملکرد غیرفعالسازی محصول و و فواصل تجمیع معیارهای پیکربندی شده، یک تا 2 دقیقه طول کشید تا تأثیر بگذارد:
معماری R2 سرویس Gateway، مسئول احراز هویت و ارائه درخواستها به APIهای S3 و REST R2، را جدا میکند و درب ورودی برای R2 به شمار میرود که ذخیره ابرداده مبتنی بر اشیاء پایا، حافظههای پنهان میانی ما و زیرسیستم ذخیرهسازی توزیعشده زیربنایی مسئول نگهداری پایدار است.

در طول این حادثه، تمام اجزای دیگر R2 فعال باقی ماندند: این همان چیزی است که به سرویس اجازه میدهد پس از بازیابی و استقرار مجدد سرویس R2 Gateway به سرعت بازیابی شود. زمانی که عملیاتها علیه R2 انجام میشود، درگاه R2 به عنوان هماهنگ کننده برای همه کارها عمل میکند. در طول چرخه درخواست، احراز هویت و مجوز را تأیید میکنیم، هر داده جدید را در یک کلید تغییرناپذیر جدید در ذخیرهسازی هدف خود مینویسیم، سپس لایه ابرداده خود را برای اشاره به هدف جدید بهروزرسانی میکنیم. وقتی سرویس غیرفعال شد، تمام فرآیندهای در حال اجرا متوقف شدند.
درحالیکه تمام درخواستهای فعلی و بعدی با شکست مواجه میشوند، هر چیزی که پاسخ HTTP 200 را دریافت کرده بود، قبلاً بدون خطر بازگشت به نسخه قبلی در هنگام بازیابی سرویس، موفق شده بود. این برای تضمینهای سازگاری R2 بسیار مهم است و شانس دریافت پاسخ API موفقیتآمیز توسط کلاینت را بدون تغییر زیرساخت ابرداده و ذخیرهسازی کاهش میدهد.
به دلیل خطای انسانی و آموزشهای ناکافی در ابزار مدیریت ما، سرویس R2 Gateway به عنوان بخشی از یک اصلاح معمول برای URL فیشینگ حذف شد.
در یک اصلاح معمول، اقدامی در مورد شکایتی انجام شد که بهطور سهوی سرویس R2 Gateway را بهجای نقطه پایانی مرتبط با گزارش غیرفعال کرد. این مشکل به دلیل نقض چندین کنترل سطح سیستم (اول و مهمتر از همه) و آموزش اپراتور بود.
یک کنترل کلیدی در سطح سیستم که منجر به این حادثه شد نحوه شناسایی یا برچسب کردن حسابهای داخلی مورد استفاده تیمهایمان بود. تیمها معمولاً چندین حساب دارند (dev، staging، prod) تا شعاع انفجار هر گونه تغییر پیکربندی یا استقرار را کاهش دهند، اما سیستمهای پردازش سوء استفاده ما به طور صریح برای شناسایی این حسابها و مسدود کردن اقدامات غیرفعال کردن آنها پیکربندی نشده است. به جای غیرفعال کردن نقطه پایانی خاص مرتبط با گزارش سوءاستفاده، سیستم به اپراتور اجازه داد تا سرویس R2 Gateway را (به اشتباه) غیرفعال کند.
با بررسی این موضوع، به دلیل فقدان کنترلهای مستقیم برای بازگرداندن اقدام غیرفعال کردن محصول و نیاز به درگیر کردن یک تیم عملیاتی با دسترسی سطح پایینتر از حد معمول، اصلاح و بازیابی متوقف شد. سپس سرویس R2 Gateway به استقرار مجدد نیاز داشت تا بتواند مسیریابی خود را در سراسر شبکه ما بازسازی کند.
پس از استقرار مجدد، مشتریان میتوانستند دوباره به R2 متصل شوند و نرخ خطا برای سرویسهای وابسته (از جمله Stream، Images، Cache Reserve و Vectorize) به سطوح عادی بازگشت.
مراحل اصلاح و پیگیری
ما اقدامات فوری را برای رفع شکافهای اعتبارسنجی در ابزار خود انجام دادهایم تا از وقوع این شکست خاص در آینده جلوگیری کنیم.
ما چندین جریان کاری را برای اجرای کنترلهای قویتر و گستردهتر سیستم و جلوگیری از این موضوع اولویتبندی میکنیم، از جمله اینکه چگونه حسابهای داخلی را ارائه میکنیم تا به تیمهای خود برای برچسبگذاری صحیح و مطمئن حسابها اعتماد نکنیم. یک موضوع کلیدی در تلاشهای اصلاحی ما در اینجا، حذف نیاز به تکیه بر آموزش یا فرآیند است و در عوض اطمینان از اینکه سیستمهای ما دارای حفاظهای مناسب و کنترلهای داخلی برای جلوگیری از خطاهای اپراتور هستند.
این جریانهای کاری شامل (اما نه محدود به) موارد زیر است:
انجام شده: حفاظهای اضافی در «Admin API» برای جلوگیری از غیرفعال کردن سرویسهای در حال اجرا در حسابهای داخلی توسط محصول اجرا شده است.
انجام شده: اقدامات غیرفعال کردن محصول در رابط کاربری بررسی سوءاستفاده غیرفعال شده است در حالیکه ما حفاظتهای قویتری اضافه میکنیم. این امر از تکرار ناخواسته اقدامات دستی پرخطر مشابه جلوگیری میکند.
حین انجام: تغییر نحوه ایجاد همه حسابهای داخلی (مرحلهسازی، توسعه، تولید) برای اطمینان از اینکه همه حسابها به درستی در سازمان درست ارائه میشوند. این قسمت باید شامل محافظت در برابر ایجاد حسابهای مستقل باشد تا از وقوع مجدد این حادثه (یا مشابه آن) در آینده جلوگیری شود.
حین انجام: محدود کردن بیشتر دسترسی به اقدامات غیرفعال کردن محصول فراتر از اصلاحات توصیه شده توسط سیستم برای گروه کوچکتری از اپراتورهای ارشد.
حین انجام: برای اقدامات غیرفعال کردن محصول موقت، تأیید 2 طرفه نیاز است. در آینده، اگر بازپرس به اصلاحات اضافی نیاز داشته باشد، باید به مدیر یا فردی که در لیست پذیرش اصلاحیه تأیید شده ما است، ارسال شود تا اقدامات اضافی آنها در مورد گزارش سوءاستفاده را تأیید کند.
حین انجام: گسترش بررسیهای سوء استفاده موجود که از مسدود شدن تصادفی نامهای میزبان داخلی جلوگیری میکند تا از هرگونه اقدام غیرفعال کردن محصول مربوط به محصولات مرتبط با حساب داخلی Cloudflare نیز جلوگیری شود.
حین انجام: حسابهای داخلی قبل از انتشار عمومی این ویژگی به مدل سازمانهای جدید ما منتقل میشوند. حساب تولید R2 یکی از اعضای این سازمان بود، اما موتور اصلاح سوءاستفاده ما از محافظتهای لازم برای جلوگیری از اقدام علیه حسابهای درون این سازمان برخوردار نبود.
ما همچنان به بحث و بررسی گامها و تلاشهای اضافی ادامه میدهیم که میتواند به کاهش تأثیر مشکل هر سیستم یا عمل انسانی شود که میتواند منجر به غیرفعال کردن هر سرویس تولیدی در Cloudflare شود.
نتیجهگیری
ما میدانیم که این یک حادثه جدی بود و به شدت از تأثیری که بر مشتریان و تیمهایی که کسبوکارشان را در Cloudflare ایجاد و راهاندازی میکنند، آگاه و بسیار متأسف هستیم.
این اولین (و در حالت ایدهآل، آخرین) رویداد از این نوع برای R2 است و ما متعهد به بهبود کنترلها در سیستمها و گردش کار خود برای جلوگیری از این اتفاق در آینده هستیم.»






